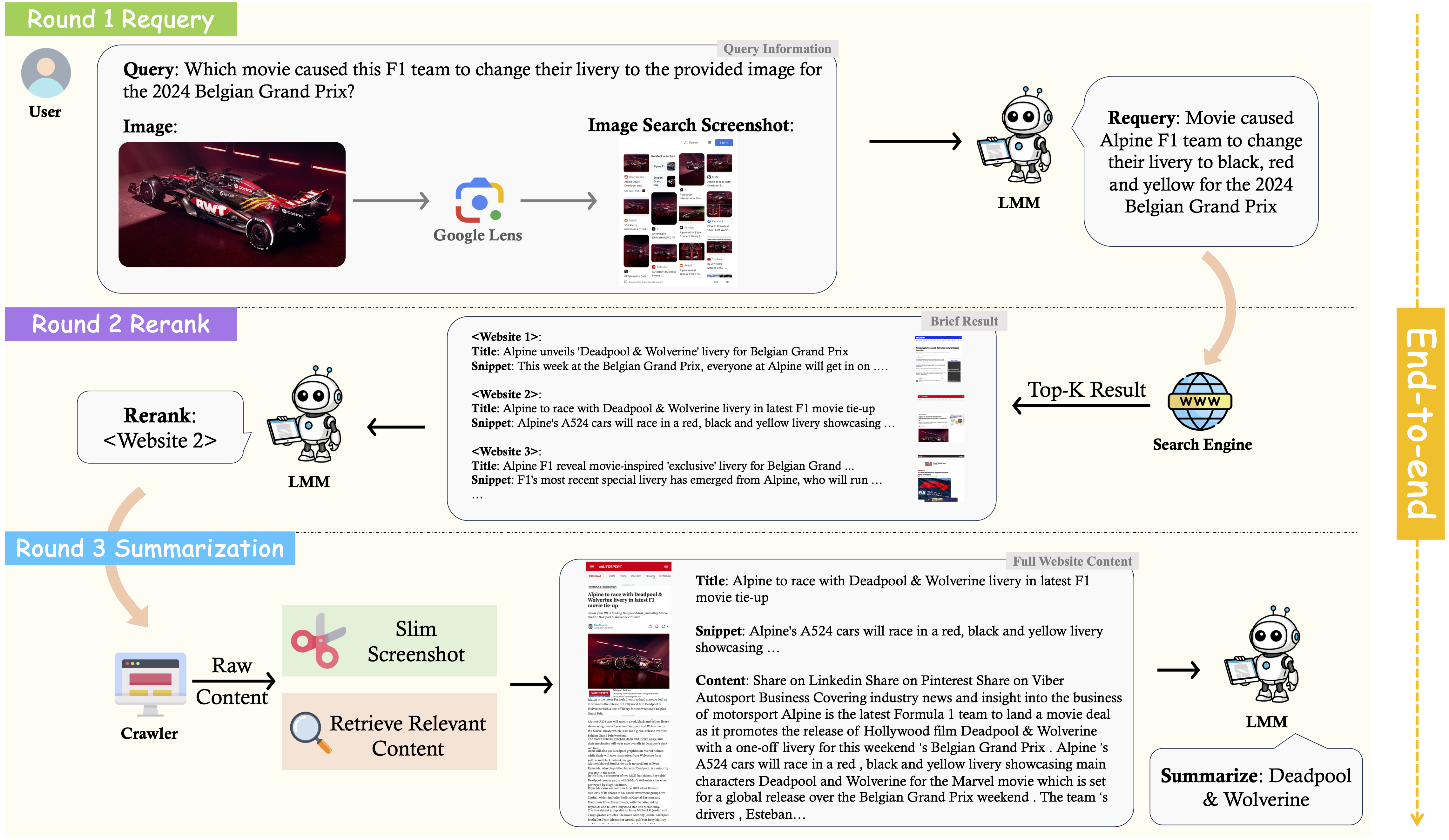
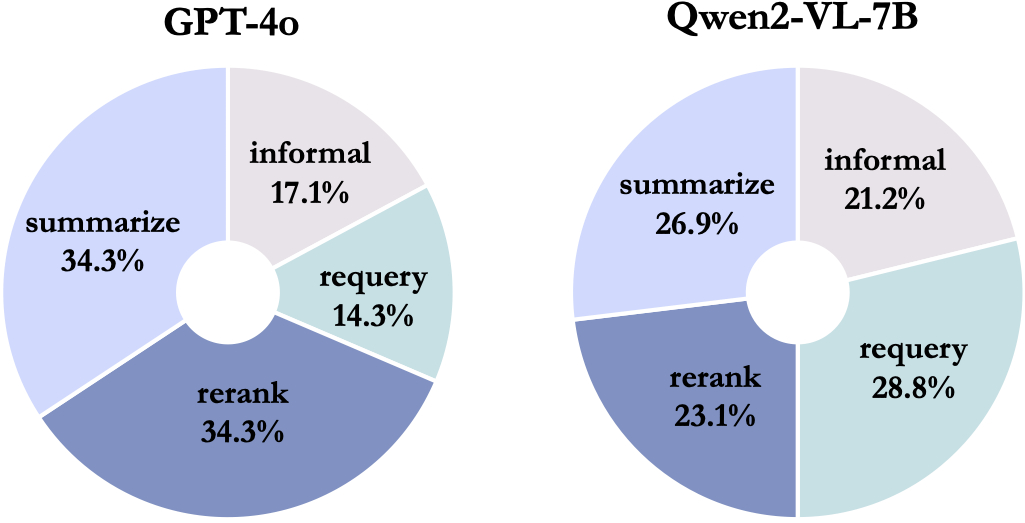
Final scores and scores of each task on the ![]() MMSearch.
MMSearch.
| # | Model | Date | All | End-to-end | Requery | Rerank | Summarize | ||||||||||
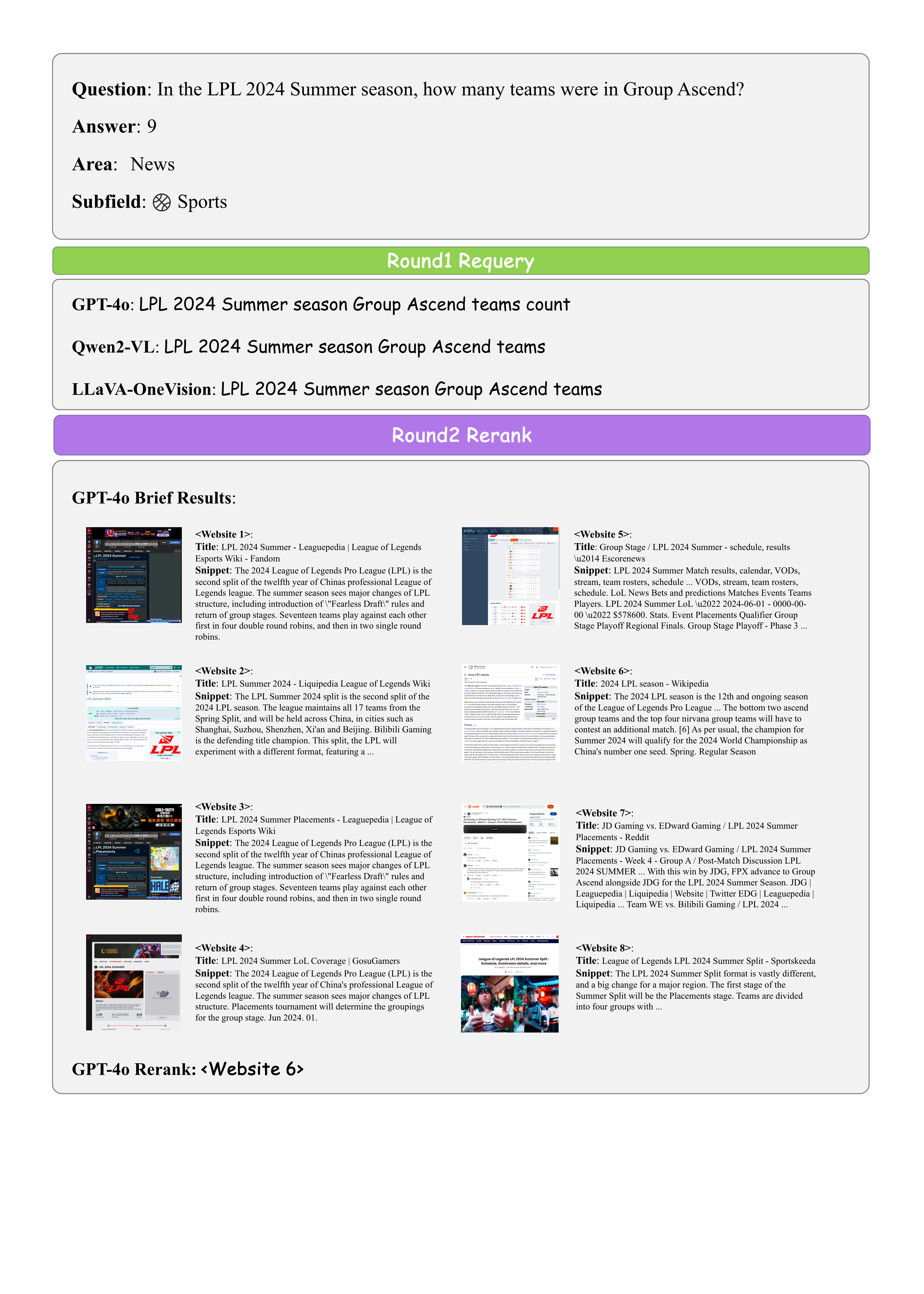
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg | News | Know. | Avg | News | Know. | Avg | News | Know. | Avg | News | Know. | Avg | News | Know. | 1 | GPT-4o 🥇 | 2024-05 | 62.3 | 61.2 | 65.3 | 60.4 | 59.0 | 64.5 | 46.8 | 49.9 | 38.0 | 83.0 | 82.4 | 84.8 | 63.1 | 62.2 | 65.6 |
| 2 | GPT-4V 🥈 | 2023-09 | 55.0 | 55.0 | 55.3 | 52.1 | 52.2 | 51.9 | 45.7 | 49.2 | 35.8 | 79.3 | 76.9 | 86.1 | 57.4 | 56.7 | 59.4 |
| 3 | Claude 3.5 Sonnet 🥉 | 2024-06 | 53.5 | 53.1 | 54.7 | 49.9 | 49.3 | 51.6 | 42.0 | 43.6 | 37.7 | 80.2 | 78.7 | 84.2 | 59.4 | 60.3 | 57.0 |
| 4 | Qwen2-VL-AnyRes-72B | 2024-08 | 52.7 | 52.0 | 54.5 | 49.1 | 48.8 | 49.8 | 44.7 | 47.2 | 37.6 | 76.7 | 72.9 | 87.3 | 59.6 | 57.5 | 65.7 |
| 5 | LLaVA-OneVision-72B | 2024-08 | 50.1 | 50.1 | 50.2 | 44.9 | 45.1 | 44.1 | 42.9 | 45.9 | 34.3 | 82.2 | 80.5 | 86.7 | 61.4 | 59.1 | 67.7 |
| 6 | Qwen2-VL-AnyRes | 2024-08 | 45.3 | 44.1 | 48.7 | 40.3 | 39.2 | 43.5 | 39.0 | 41.9 | 30.8 | 76.7 | 73.8 | 84.8 | 54.7 | 52.7 | 60.4 |
| 7 | LLaVA-OneVision | 2024-08 | 36.6 | 39.4 | 28.9 | 29.6 | 33.1 | 19.7 | 35.8 | 40.3 | 23.2 | 72.8 | 73.5 | 70.9 | 53.5 | 51.8 | 58.5 |
| 8 | Idefics3 | 2024-08 | 36.2 | 38.5 | 29.6 | 29.3 | 32.3 | 20.8 | 31.0 | 37.3 | 13.5 | 76.5 | 73.3 | 85.4 | 50.3 | 51.1 | 48.1 |
| 9 | Idefics3-AnyRes | 2024-08 | 35.7 | 38.2 | 28.7 | 30.1 | 32.9 | 22.3 | 27.2 | 32.2 | 13.2 | 72.7 | 73.1 | 71.5 | 45.2 | 46.3 | 42.1 |
| 10 | InternVL2 | 2024-07 | 34.3 | 35.7 | 30.2 | 30.9 | 32.5 | 26.2 | 32.3 | 36.1 | 21.6 | 46.5 | 49.3 | 38.6 | 48.5 | 45.9 | 55.8 |
| 11 | InternVL2-AnyRes | 2024-07 | 34.1 | 34.2 | 33.7 | 30.0 | 30.3 | 29.0 | 31.4 | 35.5 | 19.7 | 53.2 | 52.3 | 55.7 | 46.9 | 44.4 | 53.7 |
| 12 | mPlug-Owl3-AnyRes | 2024-08 | 33.9 | 35.5 | 29.3 | 27.3 | 29.4 | 21.2 | 31.8 | 36.1 | 19.9 | 74.5 | 72.9 | 79.1 | 43.9 | 43.6 | 44.6 |
| 13 | mPlug-Owl3 | 2024-08 | 32.1 | 34.8 | 24.4 | 24.6 | 28.1 | 14.9 | 32.6 | 36.7 | 21.2 | 74.3 | 73.5 | 76.6 | 45.6 | 45.6 | 45.4 |
| 14 | LLaVA-NeXT-Interleave | 2024-06 | 28.3 | 29.2 | 25.6 | 23.0 | 23.8 | 20.5 | 26.2 | 30.7 | 13.5 | 55.3 | 58.6 | 46.2 | 42.5 | 40.0 | 49.3 |
| 15 | InternLM-XC2.5-AnyRes | 2024-07 | 22.3 | 23.9 | 17.5 | 23.2 | 25.4 | 16.9 | 21.7 | 19.8 | 26.9 | 0.0 | 0.0 | 0.0 | 37.7 | 38.6 | 35.1 |
| 16 | InternLM-XC2.5 | 2024-07 | 22.2 | 22.8 | 20.5 | 22.9 | 23.6 | 20.8 | 25.0 | 24.3 | 27.0 | 0.0 | 0.0 | 0.0 | 37.7 | 38.6 | 35.0 |
| 17 | Mantis | 2024-05 | 18.7 | 19.8 | 15.9 | 15.8 | 16.4 | 14.3 | 20.1 | 24.6 | 7.4 | 39.7 | 41.0 | 36.1 | 19.2 | 22.0 | 11.5 |
| - | Human | - | 69.2 | 69.6 | 68.1 | 68.2 | 68.6 | 67.1 | 43.7 | 45.0 | 40.1 | 85.7 | 87.3 | 81.2 | 72.8 | 71.4 | 76.7 |
Human Performance*: Average human performance from annotators that are college students.